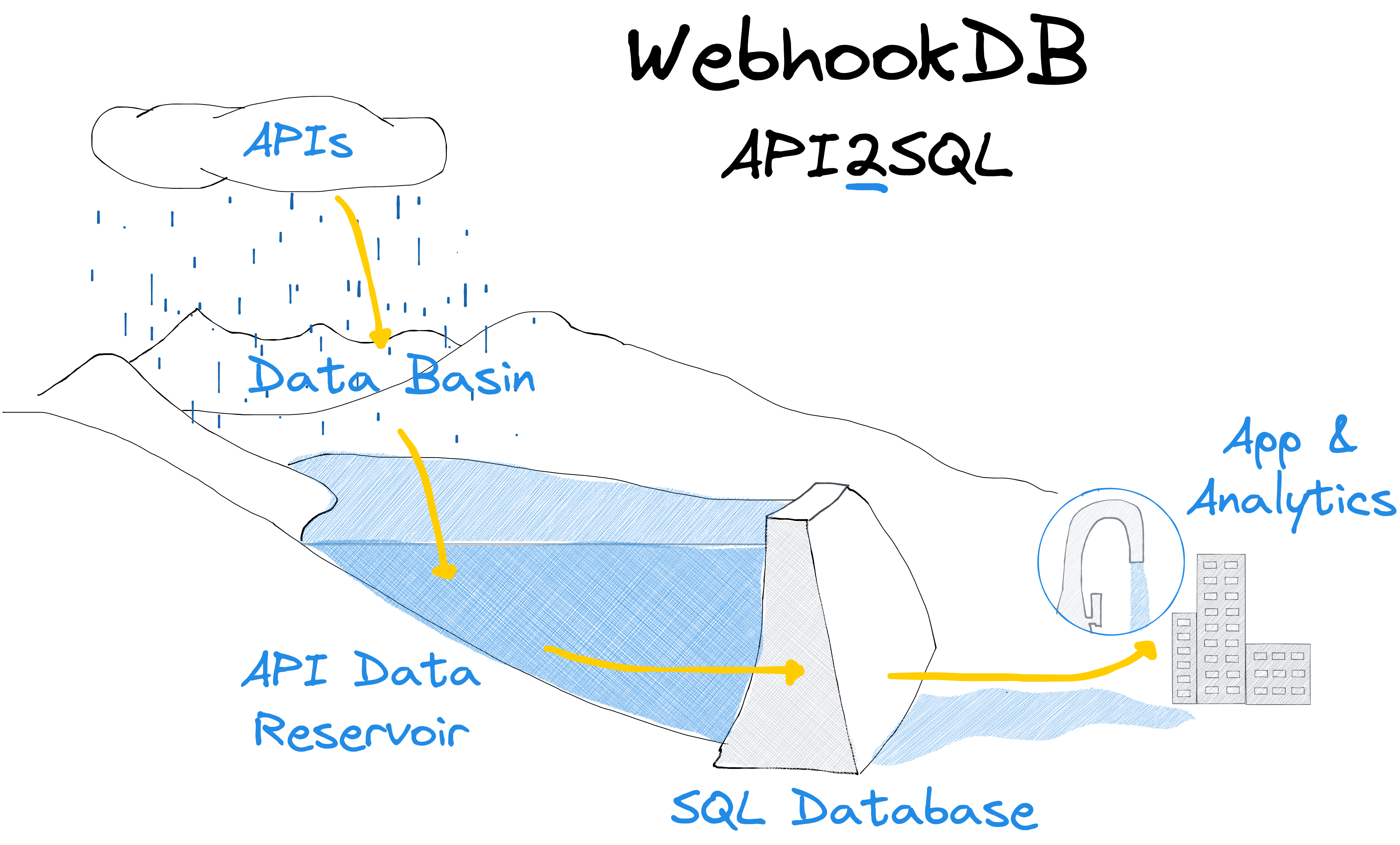
The API Data Reservoir
WebhookDB is modeled after the way a reservoir works.
Reservoirs for water have the following key components:
- Rain, springs, and snow melt, which happen over a wide area.
- The Basin collects this water and channels it towards a valley.
- The Dam is built at the narrow point of the valley.
- The Lake (or Reservoir) is the lake that forms behind the dam.
- Treatment plants take this relatively clean lake water and ensure it is safe for human consumption.
- Water is then piped to where we need it, when we need it, providing most of the drinking water in the world.
WebhookDB works the same way:
- APIs (your own and 3rd parties) produce data, lots of data, unique to the API.
- WebhookDB workers collect this data into a Data Basin using webhooks, periodic polling, and more.
- This data is schematized and normalized into the Data Reservoir.
- An SQL database (Postgres, though MySQL is in alpha) acts as the Dam, giving you access to the reservoir.
- Because it is just an SQL database, the data can use your existing pipes; there’s no need to learn, deploy, and manage new technology or services on your critical path, like GraphQL or gRPC.
If you want to make integrating APIs as simple as turning on a tap, you can try WebhookDB today.
 </img>
</img>